
Training a modern large language model (LLM) is less about writing clever code and more about moving massive amounts of data fast enough to keep thousands of GPUs busy. If your storage system can’t feed data to the compute cluster quickly, those expensive chips sit idle. This bottleneck becomes critical when dealing with petabyte-scale datasets, which are collections of training data exceeding one million gigabytes, requiring specialized infrastructure for efficient access. Without proper data sharding, defined as the process of splitting large datasets into smaller, manageable chunks called shards to enable parallel processing, even the most powerful hardware clusters will stall.
The Core Problem: Memory and Throughput Bottlenecks
Why do we need sharding in the first place? It comes down to memory constraints and network bandwidth. During training, a GPU needs to hold three things simultaneously: model parameters, gradients, and optimizer states. This requirement often triples or quintuples the memory needed compared to simple inference tasks. The rough formula is:
Memory Requirement ≈ α × Model Size, where α is typically between 3 and 5.
Even with half-precision formats like float16 or bfloat16, which cut memory use by 50%, fitting a 70-billion-parameter model into a single GPU’s VRAM is impossible. You must distribute the workload. But distributing the model is only half the battle. You also have to distribute the data so that every GPU gets its fair share without waiting on a slow central server.
If you try to read from a standard file system across a network, the latency kills performance. That’s why the industry has shifted toward tiered storage architectures designed specifically for high-throughput data loading.
Tiered Storage Architecture for LLM Training
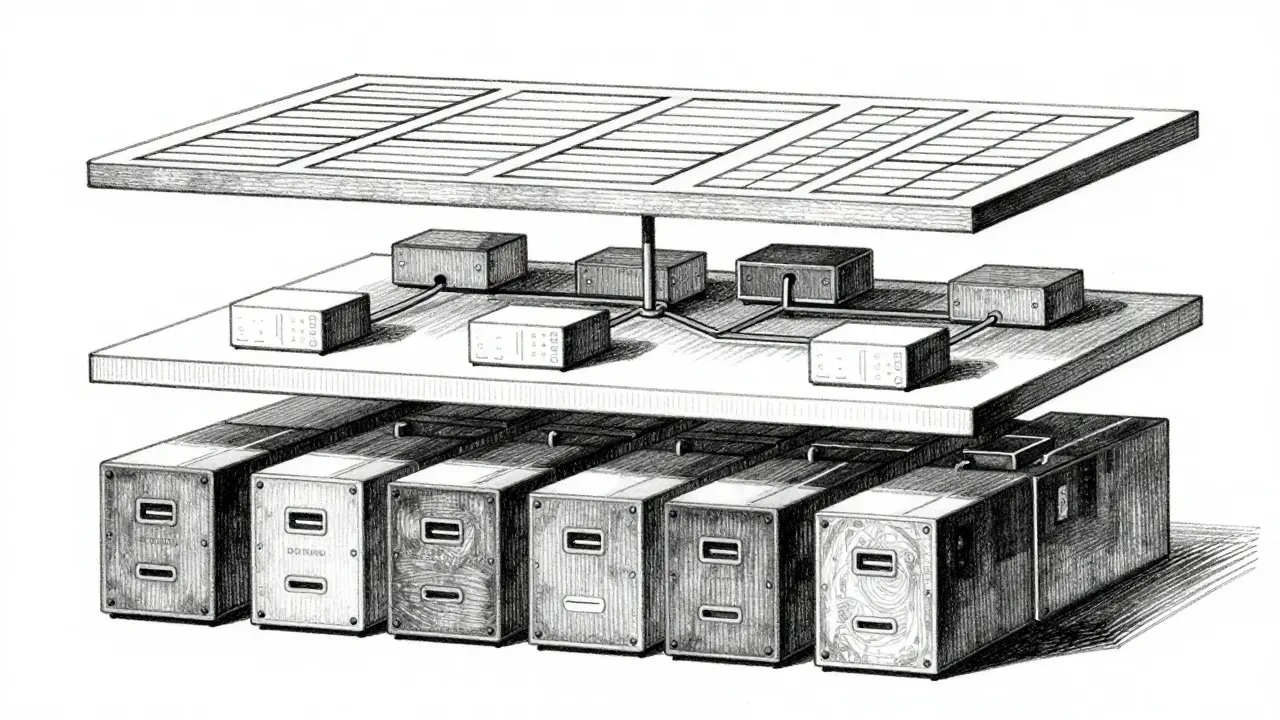
You cannot treat all storage equally. A cost-effective architecture uses different layers for different stages of the data lifecycle. Here is how top-tier MLOps teams structure their storage:
- Primary Cold Storage: Object storage systems like AWS S3, Amazon Web Services' scalable object storage service used for long-term dataset retention, Google Cloud Storage, or Azure Blob Storage. This is where raw data lives. It’s cheap and durable but too slow for direct training reads.
- High-Performance Cache: Distributed file systems such as Lustre, a parallel distributed file system designed for high-performance computing environments, WekaIO, or CephFS. These sit closer to the compute cluster. They provide low-latency access for data currently being processed during training epochs.
- Data Lakehouse Layer: Technologies like Apache Iceberg, an open table format for huge analytic datasets that supports ACID transactions and schema evolution, Delta Lake, or Hudi. These add structure, metadata management, and transactional capabilities on top of object storage, allowing you to query and manage petabytes of data efficiently.
The workflow is straightforward: stage data from cold object storage to the high-performance cache before training begins. As the model trains, it pulls shards directly from this fast layer. Once an epoch is complete, updated metrics might be written back, but the raw data remains static in the cache for subsequent passes.
Sharding Strategies: From Files to Tokens
Sharding isn’t just about breaking files apart; it’s about organizing them for parallel consumption. In petabyte-scale contexts, original files (images, text documents, audio) are serialized into compressed formats like .tar, .tgz, or .tar.lz4. Each of these compressed objects is a shard.
A typical dataset might contain millions of individual shards. The key is ensuring that each shard is small enough to be loaded quickly but large enough to minimize overhead. For text-based LLMs, shards often correspond to specific token ranges or document batches.
| Approach | Best For | Pros | Cons |
|---|---|---|---|
| File-Based Sharding | Image/Multimodal Data | Simple implementation, easy debugging | Higher I/O overhead, uneven load distribution |
| Token-Based Sharding | Text LLMs | Uniform batch sizes, optimal GPU utilization | Complex preprocessing, requires careful alignment |
| Category-Based Sharding | Fine-Tuning/Domains | Preserves domain balance, enables stratified sampling | Requires metadata mapping, potential bias if not shuffled |
For example, when working with ImageNet-style data, you might use category-based sharding to group similar images together. Tools like ishard, a utility for creating flexible, categorized shards from arbitrarily structured datasets, allow you to map samples to output shards based on external keys. This lets you treat 'tench' and 'goldfish' as a single 'fish' category during preprocessing, simplifying downstream classification tasks.
Data Loading Frameworks: Keeping GPUs Busy
Having sharded data is useless if your loader can’t fetch it fast enough. GPU idling is the enemy of training efficiency. Modern frameworks coordinate which node reads which shard, often prefetching data for upcoming batches.
Here are the primary tools in the ecosystem:
- PyTorch DataLoader + DistributedSampler: The standard approach for PyTorch users. It handles shard assignment across processes but can struggle with complex decoding tasks.
- TensorFlow tf.data: Offers built-in sharding options and pipeline optimization, ideal for TensorFlow-based workflows.
- NVIDIA DALI: Accelerates image preprocessing by offloading decoding to GPUs, significantly reducing CPU bottlenecks.
- WebDataset: Designed specifically for large-scale, distributed training. It reads shards directly from object storage or fast caches, handling compression and decompression efficiently.
In AIStore’s implementation, for instance, sharding enables global shuffling of shard names combined with client-side shuffle buffers. This ensures that the data seen by each GPU is randomized enough to prevent bias while maintaining high throughput.
Distributed Training Techniques: Sharded Data Parallelism
Once data is loaded, how do you train the model? Standard data parallelism replicates the entire model on every GPU, which wastes memory. Sharded Data Parallelism (SDP), a distributed training technique that splits optimizer states and gradients across GPUs to save memory, changes this game.
With SDP, trainable parameters, gradients, and optimizer states are sharded across GPUs in a group. Instead of every GPU holding a full copy, they hold fractions. This allows you to fit larger models or use larger batch sizes within the same memory footprint.
Consider a real-world configuration from Amazon SageMaker:
- Model: GPT-NeoX-65B
- Hardware: 64 ml.p4d.24xlarge instances (each with 8 GPUs)
- Parallelism: Degree-2 Sharded Data Parallelism + Degree-64 Tensor Parallelism
- Batch Size: 4,096 global, sequence length 512
This setup works because tensor parallelism splits the model layers across GPUs within a node, while sharded data parallelism distributes the optimizer states across nodes. Together, they solve both the memory capacity problem and the communication bottleneck.
For even larger clusters, say 1,536 GPUs (192 nodes), you might use an SDP degree of 32 with a batch size of 1 per GPU. This results in 1,536 model replicas and a global batch size of 1,536, processing approximately 6 million tokens per global batch. Combining this with tensor parallelism reduces the global batch size by half but allows for longer sequences and finer-grained control over memory usage.
Optimizing Batch Size and Avoiding OOM Errors
Choosing the right batch size is critical. Start small-batch size 1-and gradually increase until you hit out-of-memory (OOM) errors. If you hit OOM immediately, you need a higher degree of sharded data parallelism or a combination with tensor parallelism.
Remember, larger batch sizes improve convergence and generalization, but only if the data is diverse enough. Proper shuffling via sharded loaders ensures that each batch represents the broader dataset distribution, preventing the model from memorizing local patterns.
Domain Adaptation: Do You Really Need Petabytes?
While pretraining requires petabytes, recent research challenges the assumption that fine-tuning does. Domain adaptation strategies using focused, smaller datasets often achieve competitive results.
For example:
- Llama-3.1-8B: Trained on ~1 million tokens for initial specialization.
- DeepSeek-R1-Distill-Qwen-14B: Used ~50 million tokens.
- Cybersecurity LLMs: Achieved strong performance with just 118.8 million tokens, compared to 2.77 billion in older approaches.
This means your sharding strategy should be flexible. You don’t always need to shard petabytes for every task. For domain-specific fine-tuning, smaller, carefully curated shards may be more effective than massive, noisy datasets.
Practical Checklist for Implementation
To ensure your pipeline is efficient, verify these points:
- Storage Tiering: Is hot data cached on high-speed storage near the compute cluster?
- Shard Size: Are shards optimized for parallel reading (typically 100MB-1GB)?
- Loading Framework: Are you using a framework like WebDataset or DALI that supports async prefetching?
- Parallelism Strategy: Have you balanced Sharded Data Parallelism and Tensor Parallelism to avoid memory bottlenecks?
- Shuffling: Is global shuffling enabled to prevent data bias across GPUs?
What is the difference between data sharding and model sharding?
Data sharding splits the input dataset into smaller pieces so multiple workers can process them in parallel. Model sharding (or tensor parallelism) splits the model itself across devices. Both are often used together in large-scale training to maximize throughput and minimize memory usage.
Which storage solution is best for petabyte-scale LLM training?
A hybrid approach is best. Use object storage (like AWS S3) for long-term, cost-effective retention of raw data. Use a high-performance distributed file system (like Lustre or WekaIO) or a large caching layer for active training data to ensure low-latency access for GPUs.
How does Sharded Data Parallelism save memory?
Standard data parallelism replicates optimizer states and gradients on every GPU. Sharded Data Parallelism divides these states across GPUs in a group. Each GPU only stores a fraction of the total state, allowing larger models or bigger batch sizes to fit within available VRAM.
Do I need petabytes of data for fine-tuning?
Not necessarily. Recent studies show that domain adaptation can be highly effective with much smaller datasets (millions to tens of millions of tokens) if the data is high-quality and relevant. Petabytes are primarily required for initial pretraining of foundational models.
What is the role of Apache Iceberg in LLM data pipelines?
Apache Iceberg provides a table format that adds structure, schema evolution, and transactional support to data stored in object storage. It helps manage metadata and ensures consistency when dealing with massive, evolving datasets, making it easier to query and update training data without rewriting entire files.